How we use EBS and Auto Scaling groups to move database state during updates
Christoffer Ventus
Team Lead
October 12, 2020 • 7 min read
At Aito we want to make practical statistical predictions accessible to all software teams, whether you have data scientists on board or not. Our predictive database does the heavy lifting and provides a straight-forward query API where each query is automatically turned into a probabilistic model, which in turn is used to retrieve relevant content. To relieve the burden of deployment and maintenance we also host and maintain the database instances for you.
Occasionally a database instance needs to be reconfigured or updated. We use declarative infrastructure-as-code for all our provisioning, including our customers’ Aito instances. An instance is updated by launching a new instance with updated configuration and switching incoming traffic to it once it has become healthy.
This update procedure is attractive due to the simple rollback procedure: you can cancel at any time and the original instance remains intact. While the instances are mostly immutable, the database state is not. For a brief moment, there are two databases running, and the ownership of the state needs to move from one to the other. At first sight, this seemed like little more than copying files from one place to another, but it turned out to be a lot more involved than that.
Availability During Updates
We strive to maintain a good level of service at all times. The predictive query API is our most important service which should always be available. Modifying data (insertions, deletions) is also very important, but leads to technical complexity we're not able to deal with yet. For this reason we don't synchronize modifications to the state during updates. In order not to lose data we need to temporarily disable write operations. In other words, the service is temporarily degraded but read operations, like the predictive queries, remain available.
The availability requirement puts constraints on our solution. As long as the old instance receives traffic it needs to be able to answer queries. Aito databases run on EC2 instances and each has its own encrypted EBS Volume on which database state is stored. Answering queries requires state, and therefore the old instance needs its volume until the update is complete. This rules re-using the volume itself, e.g. by detaching it from the old instance and attaching it to the new. Instead we copy the contents to the new volume.
Copying State
First we need to decide how to copy state. The coarse level on which we copy (entire volumes) allows us to use EBS Snapshots rather than tools like rsync or xfs_copy. A snapshot is a complete image of a volume (partitions, filesystems, files, etc.) and can be used for more than backups. New volumes can be based on snapshots so that they're seeded with content on creation. You take snapshots through the EC2 API and this requires little to no cooperation from the EC2 Instance that the volume is attached to. You just need to make sure that everything important is flushed from I/O buffers before you do it. With snapshots you can copy an entire file system to a new instance and neither the old nor the new needs to know about one another.
Next, we need to figure out when we can start copying the state, but before we go there I need to mention something that complicates matters. Each database instance has an Auto Scaling group that manages it. While we don’t have a need for scaling in or out, the auto scaling group makes sure that there’s always one instance running and it can replace unhealthy ones. Another feature is that they can distribute instances across availability zones. We don’t pin instances to one availability zone so that when one zone is too crowded or has technical issues, instances can be migrated to another zone.
The first complication is that EBS volumes reside in one availability zone and can only be attached to EC2 instances in the same zone. Since the auto scaling group decides where the instance is launched, we can only create the new state volume after the launch. A launch template can define additional volumes that new instances should be launched with but the way it works doesn't fit our use case. A volume defined in the launch template can be created from a snapshot, which is useful when scaling out multiple EC2 instances, each with a copy of a filesystem, but our volume must be created from a snapshot that doesn't exist until the update takes place.
The second complication is that there are several reasons that a new instance is launched: when we trigger a software update, when an instance becomes unhealthy and needs to be replaced, or when the auto scaling group moves the instance to another availability zone. The last two cases are out of our control and we must somehow be notified when they happen. Luckily for us, it’s possible to hook into the launch events with lifecycle hooks. Lifecycle hooks allow us to prepare EC2 instances before they're taken into use. This is the right place to start copying the database state.
The State Migration Process
The process of copying the state volume, which we call the state migration process, requires interaction between several AWS services. It's mostly coordinated by a single AWS Lambda function (see the picture below). Lambda functions integrate well with the services we need and this being an internal process that runs with a moderately low frequency it also fits the lambda’s execution model well.
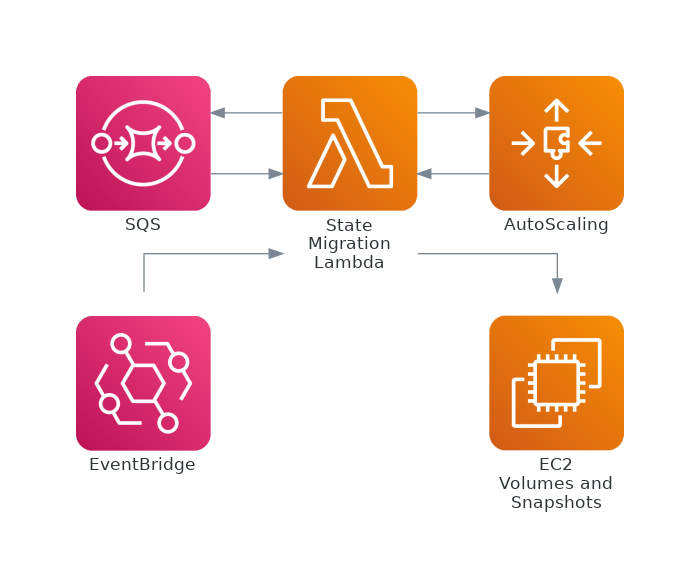
The lambda function receives events from various sources and takes the necessary actions to drive the migration process forward. Several migration processes might be ongoing at the same time, but they all follow a fairly straight-forward procedure. Let's take a look at how it works step-by-step.
Step 1: A new instance is launching
A state migration process begins when an auto scaling group sends the autoscaling:EC2_INSTANCE_LAUNCHING event. You can catch it from EventBridge, SNS, or SQS and it includes the following information:
{
"AutoScalingGroupName": "MyAutoScalingGroup",
"LifecycleTransition": "autoscaling:EC2_INSTANCE_LAUNCHING",
"LifecycleHookName": "MyInstanceLaunchingHook",
"LifecycleActionToken": "d4eeb569-d29f-476a-8fd4-d5c2520d1bd0",
"EC2InstanceId": "i-0123456789abcdef",
"NotificationMetadata": "<extra information we add when we define the hook>",
...
}Normally, an EC2 is taken into service as soon as it becomes healthy after launch but if there’s a lifecycle hook then the auto scaling group instead moves it into the Pending:Wait state. It will stay there until the migration is completed (successfully or otherwise) and we’ll later use the LifeCycleActionToken from this message to inform the auto scaling group that we’re done. The EC2InstanceId field identifies the new instance and it allows us to learn about its availability zone. Finally, we need some way of knowing which Aito database is being updated so that we can tell which volume to copy. While we can store a map from auto scaling groups to Aito databases somewhere else, it’s convenient to keep it in the NotificationMetadata field so that the launch event is unambiguous and self-contained.
The instance-launching event contains all the information we need in order to proceed but the other events we’re going to handle do not and therefore we need to record the progress of every migration in a database. The records mainly track things like snapshot and volume IDs but they are also used for synchronization because we need to be able to deal with duplicate events.
Step 2: Create a snapshot
Next we disable writes on the current database instance so that a snapshot of its volume can be taken. Snapshot creation can take a while and rather than polling for it to complete we catch the event when it appears on EventBridge. There’s, unfortunately, no support for the creation event of a certain snapshot to be sent over an SNS topic or SQS queue so we’ll have to find the relevant events in our migration code ourselves. The events are sent by the EC2 service and look something like this:
{
"detail-type": "EBS Snapshot Notification",
"source": "aws.ec2",
"resources": ["arn:aws:ec2::us-east-1:snapshot/snap-1234567"],
...,
"detail": {
"event": "createSnapshot",
"result": "succeeded",
"source": "arn:aws:ec2::us-east-1:volume/vol-1234567",
...,
}
}This event contains little more than resource IDs so we need to look in the migration database to figure out which database it belongs to. You could associate the snapshot ID you get from CreateSnapshot API with a migration process, but for us it's more convenient to use tags to achieve that, since we're going to tag the snapshots in any case. Tags can be added as part of snapshot creation and they are guaranteed to exist when we receive the event.
It's easy to miss but the snapshot and volume ARNs in the event look a little weird. First, the volume ARN doesn’t contain the account ID, which it does everywhere else. Second, the region should be the fourth field of an ARN, not the fifth. The example in the documentation is partly corrected (the volume ARN still doesn’t contain an account ID) but it doesn’t match what we actually receive. When you handle these events make sure that the ARNs are what you expect them to be.
Step 3: Create and attach the volume
With a snapshot in hand, we can now create the volume in the new EC2 instance’s region. Volumes cannot be attached to instances while they’re in the creating state, however, so we must wait for it to become available and this means that we need to handle another EC2 event. Like the createSnapshot event, the createVolume event only appears on EventBridge and looks like this
{
"detail-type": "EBS Volume Notification",
"source": "aws.ec2",
"resources": ["arn:aws:ec2:us-east-1:012345678901:volume/vol-01234567"],
...,
"detail": {
"event": "createVolume",
"result": "available",
...,
}
}This event is also pretty minimal and adding tags for identifying the migration is the way to go. When you start listening to this kind of events you’ll start receiving a lot of unrelated events. Volume creation is pretty common, e.g. each EC2 instance is typically created with one or more EBS volumes.
Ever since it entered the Pending:Wait state, the soon to be launched EC2 instance has been waiting in an init script for the state volume to appear. Our Aito software cannot start without it. Shortly after the volume has been attached, a new block device shows up on the EC2 instance and it contains a filesystem which can be mounted when the initialization proceeds. The instance is all set and it will eventually start responding to HTTP requests.
Step 4: Complete the process
After the health check of the new EC2 instance passes we complete the lifecycle hook using the token we received at the start. The auto scaling group is now free to transition the EC2 Instance from the Pending:Wait state towards the InService state. There’s one final event that’s sent when auto scaling group instances launch, and this one is signaled over EventBridge and SNS. When we receive it we mark the process as complete in the migration database, which makes the new volume the authoritative one. The next time this database instance is updated we’ll copy state from this volume.
If anything would have gone wrong during this process we only need to re-enable write operations on the old instance and tell the auto scaling group that the lifecycle hook has been abandoned.
Conclusion
Despite being mostly glue code, the lambda function turned out to be very complex. This is partly due to synchronization needs (more than one lambda function instance might handle the same event) but also due to the number of events and errors it had to handle. Having a good library for identifying and validating the structure of JSON objects helps a lot here.
The state migration process was overall more complicated than we had anticipated. Judging from the official documentation and other resources I could find, it feels like the problem we solved is quite rare. Most applications are built from completely immutable instances that access external state that’s already managed by services like RDS, and EFS, which we also tried, was not the right solution for a database. Being slightly lower down in the software stack simply requires you to deal with lower-level details. But I'm happy that AWS is configurable enough to make something like this possible.
Back to blog listAddress
Episto Oy
Putouskuja 6 a 2
01600 Vantaa
Finland
VAT ID FI34337429